


빅데이터 탐색
데이터 전처리
01) 데이터 정제
- 질적자료(Qualitative Data)
: 정성적 또는 범주형 자료라고도 하며 자료를 범주의 형태로 분류한다.
분류의 편의상 부여된 수치의 크기자체에는 의미를 부여하지 않는 자료이며
명목자료, 서열자료 등 이질적자료로 분류된다.
- 구간자료(Interval Data)
: 명목자료, 서열자료의 의미를 포함하면서 숫자로 표현된 변수에 대해서
변수 간의 관계가 산술적인 의미를 가지는 자료이다.
예) 온도(비율로 의미가 부여될 수 있는 자료가 아니며 사용연산자는 ≠ , =, ≤, ≥ , +, -)
- 비율자료(Ratio Data)
: 명목자료, 서열자료, 구간자료의 의미를 다 가지는 자료로서
수치화된 변수에 비율의 개념을 도입할 수 있는 자료이다.
예) 무게 등(사용연산자는 ≠ , =, ≤, ≥ , +, -, x, ÷)
- 데이터 정제의 과정(Processing)
: 다양한 매체로부터 데이터를 수집, 원하는 형태로 변환,
원하는 장소에 저장, 저장된 데이터의 활용가능성을 타진하기 위한
품질확인, 필요한 시기와 목적에 따라 사용이 원활하도록 관리의 과정이 필요하다.
- 전처리(Pre Processing)
: 데이터 저장 전의 처리과정으로 대상 데이터와 입수방법 결정 및 저장방식 장소를 선정한다.
* 결측 데이터의 종류
- 완전 무작위 결측(MCAR: Missing Completely At Random)
: 어떤 변수상에서 결측 데이터가 관측된 혹은
관측되지 않는 다른 변수와 아무런 연관이 없는 경우이다.
- 무작위 결측(MAR: Missing At Random)
: 변수상의 결측데이터가 관측된 다른 변수와 연관되어 있지만
그 자체가 비관측값들과는 연관되지 않은 경우이다.
- 비 무작위 결측(NMAR: Not Missing At Random)
: 어떤 변수의 결측 데이터가 완전 무작위 결측(MCAR)
또는 무작위 결측(MAR)이 아닌 결측데이터로 정의하는 즉,
결측변수값이 결측여부(이유)와 관련이 있는 경우이다.
- 평균 대치법(Mean Imputation)
: 관측 또는 실험으로 얻어진 데이터의 평균으로 결측치를 대치해서 사용한다.
평균에 의한 대치는 효율성의 향상 측면에서 장점이 있으나
통계량의 표준오차가 과소 추정되는 단점이 있다. 비조건부 평균 대치법이라고도 한다.
- 회귀 대치법(Regression Imputation)
: 회귀분석(regression)에 의한 예측치로 결측치를 대치하는 방법으로
조건부 평균 대치법이라고도 한다.
- 단순확률 대치법(Single Stochastic Imputation)
: 평균 대치법에서 추정량 표준오차의 과소 추정을 보완하는 대치법으로
Hot-deck 방법이라고도 한다.
확률 추출에 의해서 전체 데이터 중 무작위로 대치하는 방법이다.
- 최근접 대치법(Nearest-Neighbor Imputation)
: 전체표본을 몇 개의 대체군으로 분류하여 각 층에서의 응답자료를 순서대로 정리한 후
결측값 바로 이전의 응답을 결측치로 대치한다. 응답값이 여러 번 사용될 가능성이 단점이다.
- 이상치(이상값, Outlier)란 데이터의 전처리 과정에 발생 가능한 문제로
정상의 범주(데이터의 전체적 패턴)에서 벗어난 값을 의미한다.
데이터의 수집과정에서 오류가 발생할 수도 있기 때문에 이상치가 포함될 수 있다.
오류가 아니더라도 굉장히 극단적인 값의 발생으로 인한 이상치가 존재할 수도 있다.
* 이상치의 문제점
- 기초(통계적) 분석결과의 신뢰도 저하
: 평균, 분산 등에 영향을 준다. 단 중앙값은 영향이 적음을 알 수 있다.
* 이상치의 탐지
- 종속변수가 단변량(Univariate)인지 다변량(Multivariate)인지 데이터의 분포를 고려하여
모수적(Parametric) 또는 비모수적(Non-Parametric)인지에 따라
다양한 방법으로 고려해야 한다.
- 시각화(visualization)를 통한 방법(비모수적, 단변량(2변량)의 경우)
: 상자수염그림(상자그림, Box Plot), 줄기-잎 그림(Stem and Leaf Diagram)
: 산점도 그림(Scatter Plot) = 비모수적 2변량인 경우
- Z-Score 통한 방법(모수적 단변량 또는 저변량의 경우)
: 정규화를 통해 특정 threshold를 벗어난 경우를 이상치로 판별한다.
- 밀도기반 클러스터링 방법
(DBSCAN: Density Based Spatial Clustering of Appli-cation with Noise)
: 비모수적 다변량의 경우 군집간의 밀도를 이용하여
특정 거리 내의 데이터 수가 지정 개수 이상이면 군집으로 정의하는 방법이다.
정의된 군집에서 먼거리에 있는 데이터는 이상치로 간주한다.
- 고립 의사나무 방법(Isolation Forest)
: 비모수적 다변량의 경우 의사결정나무(Decision Tree) 기반으로
정상치의 단말 노드(Terminal node)보다
이상치의 노드에 이르는 길이(Path Length)가 더 짧은 성질을 이용하는 방법을 의미한다.
* 변수의 선택 방법
- 전진 선택법(Forward Selection)
: 영 모형에서 시작, 모든 독립변수 중 종속변수와 단순상관계수의 절댓값이
가장 큰 변수를 분석모형에 포함시키는 것을 말한다.
: 부분 F 검정(F test)을 통해 유의성 검증을 시행,
유의한 경우는 가장 큰 F 통계량을 가지는 모형을 선택하고
유의하지 않은 경우는 변수선택 없이 과정을 중단한다.
: 한번 추가된 변수는 제거하지 않는 것이 원칙이다.
- 후진 선택법(Backward Selection), 후진 소거법(Backward Elimination)
: 전체모델에서 시작, 모든 독립변수 중 종속변수와 단순상관계수의
절댓값이 가장 작은 변수를 분석모형에서 제외시킨다.
: 부분 F 검정을 통해 유의성 검증을 시행, 유의하지 않은 경우는 변수를 제거하고
유의한 경우는 변수제거 없이 과정을 중단한다.
: 한번 제거된 변수는 추가하지 않는다.
- 단계적 선택법(Stepwise Selection)
: 전진 선택법과 후진 선택법의 보완방법이다.
: 전진 선택법을 통해 가장 유의한 변수를 모형에 포함 후
나머지 변수들에 대해 후진 선택법을 적용하여 새롭게 유의하지 않은 변수들을 제거한다.
: 제거된 변수는 다시 모형에 포함하지 않으며 유의한 설명변수가
존재하지 않을 때까지 과정을 반복한다.
* 차원 축소
* 차원 축소의 필요성
- 복잡도의 축소(Reduce Complexity)
: 데이터를 분석하는 데 있어서 분석시간의 증가(시간복잡도: Time Complexity)와
저장변수 양의 증가(공간복잡도: Space Complexity)를 고려 시
동일한 품질을 나타낼 수 있다면 효율성 측면에서 데이터 종류의 수를 줄여야 한다.
- 과적합(Overfit)의 방지
: 차원의 증가는 분석모델 파라메터의 증가 및 파라메터 간의 복잡한 관계의 증가로
분석결과의 과적합 발생의 가능성이 커진다.
- 해석력(Interpretability)의 확보
: 차원이 작은 간단한 분석모델일수록 내부구조 이해가 용이하고 해석이 쉬워진다.
: 해석이 쉬워지면 명확한 결과 도출에 많은 도움을 줄 수 있다.
- 차원의 저주(Curse of Dimensionality)
: 데이터 분석 및 알고리즘을 통한 학습을 위해 차원이 증가하면서
학습데이터의 수가 차원의 수보다 적어져 성능이 저하되는 현상이다.
: 해결을 위해서 차원을 줄이거나 데이터의 수를 늘리는 방법을 이용해야 한다.
* 차원 축소의 방법
* 주성분 분석(PCA: Principal Component Analysis)
* PCA 특징
- 차원 축소에 폭넓게 사용된다.
- 가장 큰 분산의 방향들이 주요 중심 관심으로 가정한다.
- 본래의 변수들의 선형결합으로만 고려한다.
- 차원의 축소는 본래의 변수들이 서로 상관이 있을 때만 가능하다.
- 스케일에 대한 영향이 크다. 즉 PCA 수행을 위해선 변수들 간의 스케일링이 필수이다.
* 파생변수의 생성
* 파생변수
- 사용자가 특정 조건을 만족하거나 특정 함수에 의해 값을 만들어
의미를 부여하는 변수로 매우 주관적일 수 있으므로 논리적 타당성을 갖출 필요가 있다.
- 세분화 고객행동예측, 캠페인반응예측 등에 활용할 수 있다.
- 특정상황에만 유의미하지 않게 대표성을 나타나게 할 필요가 있다.
* 불균형 데이터 처리
- 어떤 데이터에서 각 클래스(주로 범주형 반응 변수)가 갖고 있는
데이터의 양에 차이가 큰 경우, 클래스 불균형이 있다고 말한다.
* 불균형 데이터의 문제점
- 데이터 클래스 비율이 너무 차이가 나면(Highly-imbalanced Data)
단순히 우세한 클래스를 택하는 모형의 정확도가 높아지므로 모형의 성능판별이 어려워진다.
* 불균형 데이터의 처리 방법
* 언더샘플링(Undersampling)과 오버샘플링(Oversampling)
- 언더샘플링
: 언더샘플링은 대표클래스(Majority Class)의 일부만을 선택하고,
소수클래스(Minority Class)는 최대한 많은 데이터를 사용하는 방법이다.
이때 언더샘플링된 대표클래스 데이터가 원본 데이터와 비교해 대표성이 있어야 한다.
- 오버샘플링
: 소수클래스의 복사본을 만들어, 대표클래스의 수만큼 데이터를 만들어 주는 것이다.
똑같은 데이터를 그대로 복사하는 것이기 때문에
새로운 데이터는 기존 데이터와 같은 성질을 갖게 된다.
데이터 탐색
* 데이터 탐색의 기초
* 상관분석 방법
- 피어슨 상관계수(Pearson Correlation Coefficient 또는 Pearson's r)
: 두 변수 X와 Y 간의 선형 상관관계를 계량화한 수치이다.
: 피어슨 상관계수는 +1과 -1 사이의 값을 가지며, +1은 완벽한 양의 선형 상관관계,
0은 선형 상관관계 없음, -1은 완벽한 음의 선형 상관관계를 의미한다.
: 대체로 피어슨 상관계수가 기본값이다.
- 스피어만 상관계수(Spearman Correlation Coefficient)
: 데이터가 서열자료인 경우, 즉 자료의 값 대신 순위를 이용하는 경우의 상관계수로서,
데이터를 작은 것부터 차례로 순위를 매겨 서열 순서로 바꾼 뒤 순위를 이용해
상관계수를 구한다.
: 두 변수 간의 연관 관계가 있는지 없는지를 밝혀 주며 자료에 이상점이 있거나
표본크기가 작을 때 유용하다.
* 기초통계량의 추출 및 이해
* 산포도(분산도, Degree Dispersion)
- 변동계수(CV: Coefficient of Variance)
: 평균을 중심으로 한 상대적인 산포의 척도를 나타내는 수치이다.
: 측정 단위가 동일하지만 평균이 큰 차이를 보이는 두 자료집단 또는 측정단위가
서로 다른 두 자료집단에 대한 산포의 척도를 비교할 때 많이 사용한다.
* 시각적 데이터 탐색
* 산점도(Scatter Plot)
- 직교 좌표계를 이용해 두 개 변수 간의 관계를 나타내는 방법이다.

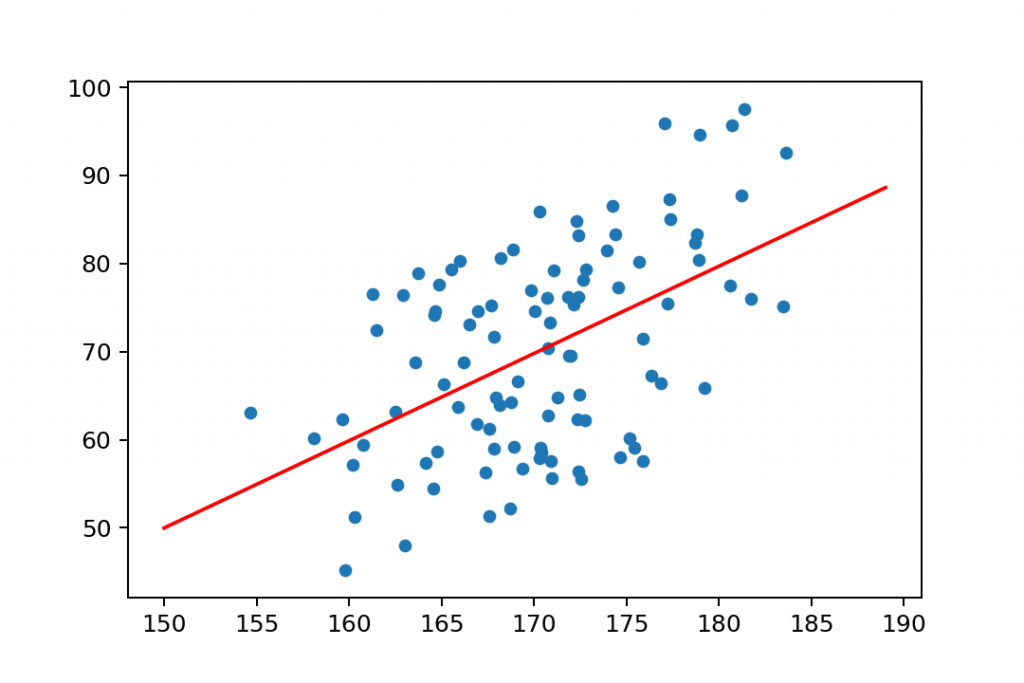{kind=link}
- 상자 수염 그림(Box Plot)
: 수치적 자료를 표현하는 그래프이다.
이 그래프는 가공하지 않은 자료 그대로를 이용하여 그린 것이 아니라,
자료로부터 얻어 낸 통계량인 5가지 요약 수치(다섯 숫자 요약, Five-number Summary)를
가지고 그린다.

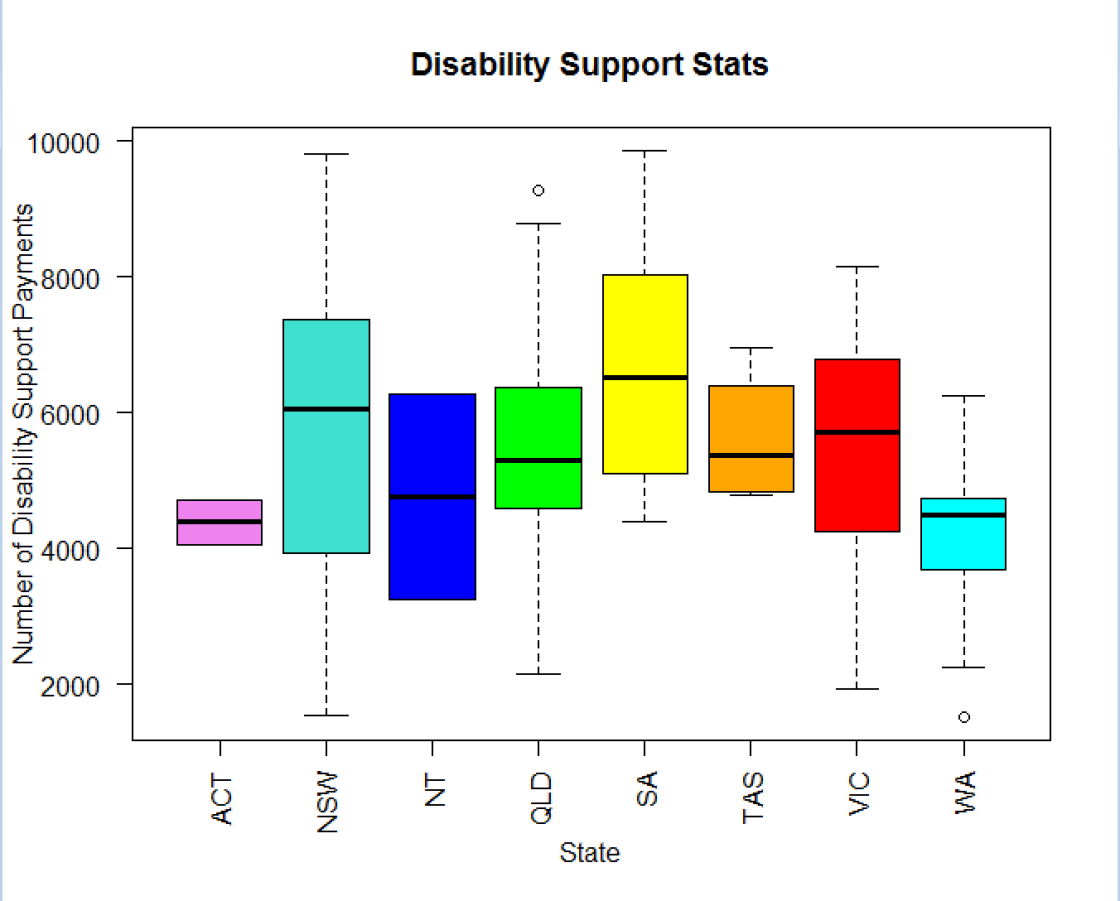{kind=link}
; 5가지 요약 수치
- 제 1사분위(Q1), 최댓값
* 고급 데이터 탐색
- 시공간 데이터
: 시간과 공간 데이터의 결합 형태를 지칭한다.
; 실체 객체들은 공간적 정보뿐만 아니라 시간적 정보와도 연관이 있다.
기본적으로 위치, 영역과 같은 공간 정보는 시간의 흐름에 따라서 변화를 하기 때문이다.
* 다변량 데이터 탐색
* 변수축약
- 주성분분석(PCA: Principal Component Analysis)
: 다변량자료에서 존재하는 비정규성(abnormality)이나 이상치(outlier)를 발견하기 위하여
변수들의 상관관계(또는 공분산)가 존재하지 않는
새로운 변수(주성분)를 구하는 것을 지칭한다.
: 주성분 분석은 N개의 변수로부터 서로 독립인 K(<N)>개의 주성분을 구해
원 변수의 차원을 줄이는 방법이다.
- 요인분석(Factor Analysis)
: 다수의 변수들의 상관관계를 분석하여 공통차원들을 통해 축약해 나가는 방법으로
이해하면 된다. 즉, 다수의 변수들 간 정보손실을 최소화하면서
소수의 요인(Factor)으로 축약하는 것이다.
- 정준상관분석(Canonical Analysis)
: 두 변수집단 간의 연관성(Association)을
각 변수집단에 속한 변수들의 선형결합(Linear Combination)의 상관계수를 이용하여
분석하는 방법이다(일반화된 상관계수).
: 상관관계의 중요성이 강하게 나타나는 분석이다.
* 비정형 데이터 탐색
- 비정형 데이터
: 비정형 데이터(Unstructured Data, Unstructured Information,
비구조화 데이터, 비구조적 데이터)는
미리 정의된 데이터 모델이 없거나 미리 정의된 방식으로 정리되지 않은 정보를 말한다.
통계기법의 이해
* 기술통계
- 표본추출 오차(Sampling Bias, Sampling Error)
: 표본에서 선택된 대상이 모집단의 특성을 과잉 대표하거나 최소 대표할 때 발생한다.
; 과잉 대표
= 중복선택 등의 원인으로 모집단이 반복, 중복된 데이터만으로 규정되는 현상을 지칭한다.
; 최소 대표
= 실제모집단의 대표성을 나타낼 표본이 아닌 다른 데이터가 표본이 되는 현상이다.
- 표본추출 시 표본의 크기(Sampling Size)보다는
대표성을 가지는 표본을 추출하는 것이 중요하다.
- 층화추출(Stratified Sampling)
: 모집단을 서로 겹치지 않게 여러 층(strata)으로 나누어
분할된 충(stra - tum)별로 배정된 표본을 단순 임의 추출법에 따라 추출하는 방법이다.
(층 : 관심을 갖고 있는 집단, 각 집단 내에 있는 추출단위들이 유사하도록 구성)
: 각 집단별 분석이 필요한 분석의 경우나 모집단 전체에 대한
특성치의 효율적 추정(추론)이 필요한 경우 시행한다.
예) 모집단의 남녀 성비가 3:2이면 표본의 성비도 3:2가 되도록 뽑는 경우
; 비례배분법
= 각 층 내의 추출단위 수에 비례하여 표본크기를 배분하는 방법
= 층 내의 변동과 조사비용은 고려하지 않고 층의 크기만을 고려한 방법
= 일반적으로 여론조사, 의식조사 등에 많이 활용됨
예) 여론 조사를 위해 한지역의 유권자의 성비가 (남:여 = 3:2) 라면
추출 표본의 성비도 남녀를 3:2 수준으로 추출
; 네이만배분법
= 각 층의 크기와 층별 변동의 정도를 동시에 고려한 표본배정 방법
= 변동의 큰 층에 대해서는 상대적으로 많은 표본을 배정
; 최적배분법
= 추정량의 분산을 최소화 시키거나 주어진 분산의 범위 하에서 비용을 최소화 시키는 방법
* 비확률 표본추출 기법
- 간편추출법(편의추출법, Convenience Sampling)
: 응답자를 선정하는 데 있어서 조사원 개인의 자의적인 판단에 따라
간편한 방법으로 표본울 추출하는 방법이다.
: 얻어진 표본이 목표모집단을 얼마나 잘 대표하는지 알 수 없고,
얻어진 통계치에 대한 통계적 정확성을 평가할 수 없다.
예) 어떤 특정장소를 지나가는 사람들을 대상으로 여론조사를 하는 경우
- 판단추출법(Judgement Sampling)
: 조사자가 나름의 지식과 경험에 의해 모집단을 가장 잘 대표한다고 여겨지는
표본을 주관적으로 선정하는 방법이다.
: 판단추출법에 의한 표본은 조사자의 주관적 판단에 의해서 표본이 추출되기 때문에
그 표본을 통해 얻은 추정치의 정확성에 대해 객관적으로 평가할 수 없다.
: 표본의 크기가 작은 경우에 조사의 오차를 좌우하는 요인은 추정량의 분산이 될 수 있다.
예) 어느 교육연구소의 연구원이 전체 학생들의 평균성적을 알아보기 위해
전체 학생들의 성적을 대표한다고 생각되는 몇 학교를 나름대로 선택하는 경우
- 할당추출법(Quota Sampling)
: 조사목적과 밀접하게 관련되어 있는 조사대상자의 연령이나 성별과 같은
변수값에 따라 모집단을 부분집단으로 구분하고, 모집단의 부분집단별 구성비율과
표본의 부분집단별 구성비율이 유사하도록 표본을 선정하는 방법이다.
: 비용이 적게 들고 손쉽기 때문에 단기간에 조사를 해야하는 경우에 알맞은 방법이다.
예) 어느 대학에서 학생 서비스 만족도를 조사하고자 한다면
기존의 자료에 의거하여 각 학과별, 학년별, 성별 구성비율을 알아본 다음,
그 비율에 따라 표본을 학과별, 학년별, 성별로 할당
- 눈덩이추출법(Snowball Sampling)
: 접근이 어렵거나 추출틀(Sampling Frame)의 작성이 곤란한
특정한 집단에 대한 조사에서 사용되는 방법이다.
: 먼저 해당 집단에 속하는 것을 사전에 알고 있는 사람들을 대상으로,
해당 집단에 속하는 다른 사람들을 소개받아서 조사를 진행하는 방법이다
(이와 같은 소개과정을 통해서 표본은 눈덩이처럼 점점 커지게 됨).
예) 폭력조직원들의 약물사용 실태를 조사할 경우,
대학교수들의 금융투자자산에 대한 인식 조사를 할 경우
* 확률분포
* 이산확률분포의 종류
- 이항분포(Binomial Distribution, X~B(n,p))
: 베르누이 시행을 n번 독립적으로 시행할 때 성공횟수를 X로 정의한 이산확률분포이다.
*연속확률분포의 종류
- 지수분포(Exponential Distribution, X~Exp(β))
: 사건이 서로 독립적일 때,
일정 시간 동안 발생하는 사건의 횟수가 포아송분포를 따른다면,
다음 사건이 일어날 때까지의 대기시간(β)에 대한 확률이 따르는 분포이다.
즉 포아송과정에서 한 개의 사건이 발생할 때까지의 대기 시간을 의미한다.
- 포아송분포와의 관계
: 포아송분포는 단위 시간당 발생하는 사건의 횟수를 관측한다.
반면 지수분포는 사건이 일어날 때까지의 대기 시간을 관측하는데 관심이 있는 것이다.
즉, 지수분포는 대기시간, 포아송분포는 횟수이다.
- 정규분포(Normal Distribution, X-N(μ, σ 2 ))
: 정규분포는 19세기의 위대한 수학자 Carl Friedrich Gauss에 의해
물리학과 천문학 등에 폭넓게 응용되기도 하였는데
이러한 연유로 정규분포를 가우스분포(Gaussian Distribution)라 부르기도 한다.
정규분포는 표본을 통한 통계적 추정 및 가성검정이론의 핵심이 되며,
실제로 우리가 사회적, 자연적 현상에서 접하는 여러 자료들의 분포가 정규분포를 띠게 된다.
- 스튜던트 t 분포(Student t - Distribution X~t(n-1))
: 정규분포의 평균 측정 시 주로 사용하는 분포이다.
분포의 모양은 Z~분포와 유사하다.
종 모양으로서 t=0에 대하여 대칭을 이루는데 t-곡선의 모양을 결정하는 것은 자유도이다.
- F 분포(F Distribution, X~F(k 1 , k 2))
: F 분포는 F 검정이나 분산분석 등에 주로 사용되는 분포함수이다.
* 추론통계
* 가설검정의 절차
- 가설의 설정
: 집단의 특성을 파악하기 위해서 표본을 이용한 의사결정은 오류의 가능성이 상존한다.
따라서 가설검정은 오류의 가능성을 사전에 관리하는 것이 중요하다.
오류의 허용확률을 정해 놓고 그 기준에 따라 가설의 채택이나 기각을 결정한다.
; 귀무가설(Null Hypothesis, H0)
= 현재 통념적으로 믿어지고 있는 모수에 대한 주장 또는 원래의 기준이 되는 가설이다.
= H0 : σ 2 = σ 20
; 대립가설(Alternative Hypothesis, H1)
= 연구자가 모수에 대해 새로운 통계적 입증을 이루어 내고자 하는 가설이다.
= H1 : σ 2 ≠ σ 20(양측검정), 또는 H1 : σ 2 > σ 20(단측검정:우측검정),
H1 : σ 2 < σ 20(단측검정:좌측검정)
- 표본을 통해 새롭게 주장하는 대립가설이 충분히 입증되지 못한다면,
연구자는 현재 믿어지고 있는 주장인 귀무가설을 그대로 받아들여야 할 것이다.
+ 추가
결측값의 종류
= 어떤 변수상에서 결측 데이터가 관측된
혹은 관측되지 않는 다른 변수와 아무런 연관이 없는 경우,
결측 데이터를 가진 모든 변수가 완전 무작위 결측이라면
대규모 데이터에서 단순 무작위 표본추출을 통해 처리 가능하다.
= 완전 무작위 결측은 어떤 변수상에서 결측 데이터가 관측된
혹은 관측되지 않는 다른 변수와 아무런 연관이
없는 경우로 정의한다.
표본추출오차에 관한 설명
= 최대대표라는 현상은 없다.
= 최소대표는 실제모집단의 대표성을 나타낼 표본이 아닌
다른 데이터가 표본이 되는 현상이다.
스튜던트 t 분포에서 자유도에 대한 설명
= 자유도가 클수록 정규분포에 모양이 수렴된다.
= 자유도가 1보다 클 때만
스튜던트 t 분포에서 기대값은 0이다.
= 스튜던트 t 분포는 정규분포의 평균 측정 시
주로 사용하는 분포이다.
분포의 모양은 Z-분포와 유사하다.
종 모양으로서 t=0에 대하여 대칭을 이루는데
t-곡선의 모양을 결정하는 것은 자유도이다.
= 자유도는 자료집단의 변수 중에서
자유롭게 선택 될 수 있는 변수의 수를 말한다.
기초통계량
= 산술평균, 기하평균, 최빈값은 중심화 경향 기초통계량이고
범위는 산포도(퍼짐정도)에 대한 기초통계량이다.
주성분 분석(PCA)
= 차원 축소에 폭넓게 사용된다.
어떠한 사전적 분포 가정의 요구가 없다.
= 차원의 축소는
본래의 변수들이 서로 상관이 있을 때만 가능하다
기각역에 대한 설명(임계치)
= 임계치(Critical Value) : 주어진 유의수준 α에서 귀무가설의 채택과
기각에 관련된 의사결정을 할 때, 그 기준이 되는 점이다.
서열자료는 질적자료(Qualitative Data)이다.
요인분석의 목적에는 분포분석이 없으며
요인분석의 특성상 추론통계가 아닌 기술 통계에 의한 분석이 그 특징이다.
나이대별(X) 성별(Y)과 체중(Z)
분석에 대한 모델링을 가정해 보면
X, Y, Z와 관계없이 Z가 없는 경우 :
데이터의 누락(응답 없음) → 완전 무작위 결측(MCAR)
여성(Y)은 체중공개를 꺼려 하는 경향 :
Z가 누락될 가능성이 Y에만 의존→ 무작위 결측(MAR)
젊은(X) 여성(Y)의 경우는
체중공개를 꺼리는 경우가 더 높음 → 무작위 결측(MAR)
무거운(가벼운) 사람들은 체중 공개 가능성이 적음 :
Z가 누락될 가능성이 Z값 자체에
관찰되지 않는 값에 달려 있음 → 비 무작위 결측(NMAR)
단일용인변수(독립변수)에 의해
종속변수에 대한 평균치의 차이를 검정하는 데 이용한다.
로그변환이란 어떤 수치 값을 그대로 사용하지 않고
여기에 로그를 취한 값을 사용하는 것을 말한다.
+ 추가 2
데이터의 정제에 관련한 설명
= 데이터의 정제는 수집된 데이터를 대상으로
분석에 필요한 데이터를 추출하고 통합하는 과정이다.
= 데이터로부터 원하는 결과나 분석을 얻기 위해서는
수집된 데이터를 분석의 도구 또는
기법에 맞게 다듬는 과정이 필요하다.
= 다양한 매체로부터 데이터를 수집, 저장, 변환
품질확인, 관리 필요하다.
= 데이터의 정제 과정:
수집, 저장, 변환, 품질확인,
관리의 과정을 거치며 변환은 데이터 유형의 변화
및 분석 가능한 형태로 가공을 의미한다.
기각역에 대한 설명
= 귀무가설을 기각하게 되는 검정통계량의 범위를
기각역이라 한다.
= 양측검정은 가설검정에서 기각영역이 양쪽에 있는 것이다.
= 단측검정은 가설검정이 기각영역의 어느 한쪽에만 있게 되는 경우이다.
= 임계치는 주어진 α 에서 귀무가설의 채택과
기각에 관련된 의사결정을 할 때, 그 기준이 되는 점이다.
다음 자료에 대해서 사분위 편차를 구해라 (예시)
= 8, 10, 12, 13, 15, 17, 17, 18, 19, 23, 24
= Q1 = (11+1)x(25/100)=3이므로
3번째 수치인 12이고
Q3= (11+1)(75/100)=9 이므로
9번째 수치 19이다. 따라서, 사분위편차는 19-12=7이 된다.
정답은 7이다.
불균형 데이터에 대한 설명
= 데이터에서 각 클래스가 갖고 있는 데이터의 양에 차이가 큰 경우,
클래스 불균형이 있다고 말한다.
= 클래스에 속한 데이터의 개수의 차이에 의해
발생하는 문제들을 불균형 데이터 문제
또는 비대칭 데이터 문제 라고 한다.
비정형 데이터는
변칙과 모호함이 발생함으므로 데이터베이스의 칸 형식의 폼에
저장되거나 문서에 주석화된 (의미적으로 태그된)
데이터에 비해 전통적인 프로그램을 사용하여
이해하는 것을 불가능하게 만든다.
요인분석에 대한 설명
= 요인 분석은 다수의 변수들 간의 관계(상관관계)를 분석하여
공통차원을 축약하는 통계분석 과정이다.
= 독립변수, 종속변수 개념이 없다. 주로 기술 통계에 의한 방법을 이용한다.
= 변수특성 파악을 위해 관련된 변수들이 묶임(군집)으로써
요인 간의 상호 독립성 파악이 필요하다.
정준분석의 설명
= 두 변수집단 간의 연관성을 각 변수집단에 속한 변수들의
선형결합의 상관계수를 이용하여 분석하는 방법이다.
= 정준상관계수는 정준변수들 사이의 상관계수이다.
= 두 집단에 속하는 변수들의 개수 중에서 변수의 개수가
적은 집단에 속하는 변수의 개수만큼의
정준변수 상이 만들어질 수 있다.
= 회귀분석의 경우 하나의 반응변수를 여러 개의
설명변수로 설명하고자 할 때,
가장 설명력이 높은 변수들의 선형결합을 찾아
이들 사이의 인과관계를 생각하는 반면에
정준분석에서는 이와 같은 인과성이 없다.
포아송분포를 적용할 수 있는 예
= 10시부터 11시 사이에 은행지점창구에 도착한 고객의 수
= 하루 동안 걸려오는 전화 수
= 원고집필 시 원고지 한 장당 오타의 수
상관분석의 기본가정에 대한 용어와 설명을 연결한 것
= 선형성 : 두 변인 X와 Y의 관계가 직선적인지를
알아보는 것으로 이 가정은 분포를 나타내는 산점도를
통하여 확인할 수 있다.
= 두 변인의 정규분포성 : 두 변인의 측정치 분포가 모집단에서
모두 정규분포를 이루는 것이다.
= 무선독립표본 : 모집단에서 표본을 뽑을 때
표본대상이 확률적으로 선정된다는 것이다.
= 동변량성 : X의 값에 관계없이 Y의 흩어진 정도가 같은 것을 의미한다.
다음 구매 이력에서 오렌지를 구매하면 동시에 키위를 구매할 가능성에
대해 연관규칙을 적용, 신뢰도를 계산 (예시)
= A : 키위 ,오렌지, 포도
B : 포도, 선글라스, 수박, 오렌지
C : 참외, 키위, 오렌지
D : 포도, 딸기, 수박, 바나나
= 0.67
+ 추가 3
어느 초등학교 1학년 여자아이들의 혈압자료에서
5명을 랜덤하게 택한 결과가 다음과 같다고 할 때
<102 92 98 88 104> 이를 이용하여
초등학교 여학생 혈압의 대표 값에 대한
95% 신뢰구간을 가장 근사하게 분석한 결과
= 이 표본으로부터 계산된 표본평균과 S는 각각 다음과 같다.
표본평균 = 96.80, S = 6.72
이 표본의 경우 자유도는 5-1=4이다.
표로부터 자유도가 4인 t_0.025경우는 2.78이므로
공식에 대입하면 다음이 성립한다.
목표값 = 96.8 ± 2.78(6.72/2.24) = 96.8 ± 8.32
여기서 2.24는 표본크기 5의 제곱근이다.
따라서 이 표본결과 초등학교 여자아이들의 혈압은
88에서 105 사이에 있다고 할 수 있다.
가설검정에 대한 설명
= 연구자에 의해 설정된 가설은 표본을 근거로 하여
채택여부를 결정짓게 되는데
이때 사용되는 통계량을 검정통계량이라 정의한다.
= 검정통계량의 표본분포에 따라
채택여부를 결정짓는 일련의 통계적 분석과정을 가설검정이라 하며
일반적으로 몇 단계의 절차를 거쳐 검정이 수행된다.
이상치에 대한 설명
= 이상치가 비 무작위성(Non-Randomly)을 가지고
나타나게(분포하게) 되면 데이터의 정상성(Normality) 감소를 초래하며
이는 데이터 자체의 신뢰성 저하로 연결될 가능성이 있다.
정상성이 높아지면 데이터의 신뢰도가 높아진다.
= 자료처리오류(Data Processing Error)는
복수개의 데이터셋에서 데이터를 추출·조합하여 분석 시,
분석 전의 전처리에서 발생하는 에러를 말한다.
변수변환 중 로그변환에 대한 설명
= 데이터분포의 형태가 우측으로 치우친 경우
정규분포화를 위해 로그변환을 사용한다.
= 로그변환이란 어떤 수치 값을 그대로 사용하지 않고
여기에 로그를 취한 값을 사용하는 것을 말한다.
데이터의 정의에 대한 설명
= 변수(Variable) : 각 단위에서 측정된 특성 결과이다.
= 원자료(Raw Data) : 표본에서 조사된 최초의 자료를 이야기한다.
= 관측값(Observation) : 각 조사 단위별 기록정보 또는 특성을 말한다.
= 단위(Unit) : 관찰 되는 항목 또는 대상을 지칭한다.
+ 추가 4
결측값의 종류에 대한 설명
= 완전 무작위 결측은
어떤 변수상에서 결측 데이터가 관측된
혹은 관측되지 않는 다른 변수와
아무런 연관이 없는 경우로 정의된다.
= 무작위 결측은 변수상의 결측데이터가 관측된
다른 변수와 연관되어 있지만
그자체가 비 관측값들과는 연관되지 않은 경우이다.
= 비 무작위 결측은 어떤 변수의 결측 데이터가
완전 무작위 결측 또는 무작위 결측이 아닌
결측데이터로 정의하는 것이다.
= 어떤 변수상에서 결측 데이터가 관측된
혹은 관측되지 않는 다른 변수와 아무런 연관이 없는 경우,
결측 데이터를 가진 모든 변수가 완전 무작위 결측이라면
대규모 데이터에서 단순 무작위 표본추출을 통해 처리 가능하다.
주성분 분석(PCA)에 대한 설명
= 분포된 데이터들의 특성을 설명할 수 있는
하나 또는 복수 개의 특징(주성분: Principal Component)을
찾는 것을 의미한다.
= 서로 연관성이 있는 고차원공간의 데이터를
선형연관성이 없는 저차원(주성분)으로
변환하는 과정을 거친다(직교변환을 사용).
= 기존의 기본변수들을 새로운 변수의 세트로 변환하여 차원을 줄이되
기존 변수들의 분포특성을 최대한 보존하여
이를 통한 분석결과의 신뢰성을 확보한다.
= 차원 축소에 폭넓게 사용된다.
어떠한 사전적 분포 가정의 요구가 없다.
= 차원의 축소는 본래의 변수들이 서로 상관이 있을 때만 가능하다
시공간 정의언어와 조작언어에 대한 설명
= 시공간자료 정의언어에는 시공간테이블 인덱스 및 뷰의 정의문,
변경문 등이 포함되어 있다.
= 시공간 조작언어는 객체의 삽입, 삭제, 변경 등의 검색문이 있다.
= 시공간자료 조작언어는 시간지원 연산자와
공간연산자를 포함하며
이를 통해 객체에 대한 공간관리와 이력정보를 제공한다.
= 시공간자료 정의언어에는 공간적 속성과
시간적 속성을 동시에 포함하며
시공간 테이블의 정의문은 점, 선, 면 등의
공간속성 타입이 추가되어 있다.
가설검정에 대한 설명
= 검정통계량의 표본분포에 따라
채택여부를 결정짓는 일련의 통계적 분석과정을
가설검정이라 하며 일반적으로 몇 단계의 절차를 거쳐 검정이 수행된다.
로그변환에 대한 설명
= 로그를 취하면 그 분포가 정규 분포에 가깝게 분포하는 경우가 있다.
이런 분포를 로그정규분포를 가진다고 한다.
= 로그변환을 사용하는 데이터 중 대표적인 것은 주식가격의 변동성 분석이다.
= 데이터분포의 형태가 우측의 치우친 경우 정규분포화를 위해 로그변환을 사용한다.
= 로그변환이란 어떤 수치 값을 그대로 사용하지 않고,
여기에 로그를 취한 값을 사용하는 것을 말한다.
일원분산의 정의와 특성을 연결시킨 것
= 하나의 인자에 근거하여 여러 수준으로 나누어지는 분석이다.
= 종속변수와 정수값을 갖는 요인변수가 각 하나여야 하고
요인변수가 정의되어야 한다.
= A반, B반, C반 간 성적의 평균 차이가 존재할 것이다도 일원분산분석의 예이다.
= 단일용인변수(독립변수)에 의해 종속변수에 대한 평균치의 차이를 검정하는 데 이용한다.
구간 추정과 점추정에 대한 설명
= 점추정은 모집단의 모수를 하나의 값을 추정해 주는 것이다.
= 구간추정은 모수가 포함되는 확률변수구간을 어떤 신뢰성 아래 추정하는 것이다.
= 우리가 아무리 좋은 추정방법을 사용한다고 하더라도
표본을 택하고 이 표본으로부터 계산된 추정값이
목표값을 정확하게 추정한다고 주장할 수는 없다.
= 구간추정은 점추정에 오차의 개념을 도입하여
모수가 포함되는 확률변수구간을 어떤 신뢰성 아래 추정하는 것이다.
연속확률분포
= T- 분포, 정규분포, 카이제곱분포
이산확률분포
= 포아송분포
군집추출에 대한 설명
= 모집단을 차이가 없는 여러 개 군집으로 나누어
군집 단위의 일부 또는 전체에 대한 분석을 시행한다.
= 모집단에 대한 추출기반을 마련하기가 어려운 경우
사용하면 편리하다.
= 표본크기가 같은 경우 단순 임의추출에 비해
표본오차가 증대할 가능성이 있다.
= 추출 모집단에 대해 사전지식이 많지 않은 경우 시행하는 것은
단순 무작위추출방법의 특징이다.
다중회귀분석을 하는 데 있어서 기본 가정
= 서로 다른 관찰치 간의 오차항은 상관이 없다. (오차항은 서로독립이며 공분산은 0).
모수와 모수추정 개념에 대한 설명
= 모수는 모집단의 특성을 수치화하여 나타낸 것이다.
= 모수의 추정량의 선택기준으로 불편성, 효율성, 일치성, 충분성이 있다.
= 충분성은 추정량이 모수에 대하여
가장 많은 정보를 제공할 때 그 추정량은 흥분추정량이 된다.
= 일치성 : 표본 크기가 증가할수록 좋은 추정값을 제시한다.
스튜던트 t 분포에서 자유도에 대한 설명
= 자유도는 자료집단의 변수 중에서 자유롭게 선택될 수 있는 변수의 수를 말한다.
= 자유도가 클수록 정규분포에 모양이 수렴된다.
= 자유도가 1보다 클 때만 스튜던트 t 분포에서 기대값은 0이다.
= 스튜던트 t 분포는 정규분포의 평균 측정 시 주로 사용하는 분포이다.
분포의 모양은 Z-분포와 유사하다.
종 모양으로서 t=0에 대하여 대칭을 이루는데 t-곡선의 모양을 결정하는 것은 자유도이다.
+ 추가 5
요약변수의 설명
= 수집된 정보를 분석에 맞게 종합한 변수이다.
= 데이터 마트에서 가장 기본적인 변수이다.
= 많은 분석 모델에서 공통으로 사용될 수 있어 재활용성이 높다.
이상치 발견의 통계적 기법 활용을 설명한 것
= 평균에는 집합 내 모든 데이터 값이 반영되기 때문에,
이상값이 있으면 값이 영향을 받는다.
가설검정에 대한 설명
= 검정통계량의 표본분포에 따라 채택여부를 결정짓는
일련의 통계적 분석과정을 가설검정이라 하며
일반적으로 몇 단계의 절차를 거쳐 검정이 수행된다.
시공간 정의언어와 조작언어에 대한 설명
= 시공간자료 정의언어에는 시공간테이블 인덱스 및 뷰의
정의문, 변경문 등이 포함되어 있다.
= 시공간 조작언어는 객체의 삽입, 삭제, 변경 등의 검색문이 있다.
= 시공간자료 조작언어는 시간지원 연산자와 공간연산자를
포함하며 이를 통해 객체에 대한 공간관리와
이력정보를 제공한다.
구간 추정과 점추정에 대한 설명
= 점추정은 모집단의 모수를 하나의 값으로 추정해 주는 것이다.
= 구간추정은 모수가 포함되는 확률변수구간을 어떤 신뢰성 아래 추정하는 것이다.
= 우리가 아무리 좋은 추정방법을 사용한다고 하더라도
표본을 택하고 이 표본으로부터 계산된 추정값이
목표값을 정확하게 추정한다고 주장할 수는 없다.
질적자료의 설명
= 서열자료는 수치나 기호가 서열을 나타내는 자료이다.
= 서열자료는 질적자료이다.
이상치에 대한 설명
= 자료처리오류는 복수개의 데이터셋에서 데이터를 추출, 조합하여
분석 시, 분석 전의 전처리에서 발생하는 에러를 말한다.
= 비 모수적 이상치를 탐지하는 방법 중에는 산점도 그림을 이용한 방법이 있다.
= 의도적 아웃라이어의 예는 남성의 키를 조사 시
의도적으로 키를 높게 기입하는 경우 등이 있다.
확률에 대한 설명
= 표본공간 S의 각 근원 사건이 일어날 가능성이 동등할 때,
사건 A에 대하여 n(A)/n(S)를 사건 A의 수학적 확률이라고 한다.
= 통계적 확률은 일반적인 자연 현상이나 사회 현상에서
일어날 가능성이 동일한 현상은 드물고
분명하지 않은 경우가 대부분이다.
= 확률은 통계적 현상의 확실함의 정도를 나타내는 척도이며,
랜덤 시행에서 어떠한 사건이 일어날 정도를
나타내는 사건에 할당된 수들을 말한다.
= 이론적으로 값은 통계적 확률 시행을 무한 번 반복 시행하면
수학적 확률을 값으로 수렴한다.
+ 추가 6
데이터마이닝에 대한 설명
= 대규모로 저장된 데이터 안에서
체계적이고 자동적으로 통계적 규칙이나
패턴을 분석하여 가치 있는 정보를 추출하는 과정이다.
= 데이터베이스 쪽에서 발전한 OLAP(온라인 분석 처리),
인공지능 진영에서 발전한 SOM,
신경망, 전문가 시스템 등의 기술적인 방법론이 쓰인다.
= 자료가 현실을 충분히 반영하지 못한 상태에서
정보를 추출한 모형을 개발할 경우 잘못된 모형을 구축할 수 있다.
이상치에 대한 설명
= 자료처리오류는 복수개의 데이터셋에서
데이터를 추출,조합하여 분석 시,
분석 전의 전처리에서 발생하는 에러를 말한다.
= 비 모수적 이상치를 탐지하는 방법 중에는 산점도그림을 이용한 방법이 있다.
= 의도적 아웃라이어의 예는 남성의 키를 조사 시
의도적으로 키를 높게 기입하는 경우 등이 있다.
기각역에 대한 설명
= 귀무가설을 기각하게 되는 검정통계량의 범위를 기각역이라 한다.
= 양측검정은 가설검정에서 기각영역이 양쪽에 있는 것이다.
= 단측검정은 가설검정이 기각영역의 어느 한쪽에만 있게 되는 경우이다.
= 임계치는 주어진 유의수준 a에서 귀무가설의 채택과
기각에 관련된 의사결정을 할 때, 그 기준이 되는 점이다.
시공간 정의언어와 조작언어에 대한 설명
= 시공간자료 정의언어에는 시공간테이블 인덱스 및 뷰의
정의문, 변경문 등이 포함되어 있다.
= 시공간 조작언어는 객체의 삽입, 삭제, 변경 등의 검색문이 있다.
= 시공간자료 조작언어는 시간지원 연산자와 공간연산자를 포함하며
이를 통해 객체에 대한 공간관리와 이력정보를 제공한다.
= 시공간자료 정의언어에는 공간적 속성과 시간적 속성을
동시에 포함하며 시공간 테이블의 정의문은
점,선,면 등의 공간속성 타입이 추가되어 있다.
차원축소 필요성에 대한 설명
= 데이터를 분석하는 데 있어서 분석시간의 증가와 저장변수 양의
증가를 고려시 동일한 품질을 나타낼 수 있다면
효율성 측면에서 데이터 종류의 수를 줄여야 한다.
= 차원이 작은 간단한 분석모델일수록 내부구조 이해가 용이하고 해석이 쉬워진다.
= 작은 차원만으로 안정적인 결과를 도출해낼 수 있다면
많은 차원을 다루는 것보다 효율적이다.
= 차원의 증가는 분석모델 파라메터의 증가 및 파라메터 간의
복잡한 관계의 증가로 분석결과의 과적합 발생의 가능성이 커진다.
이것은 분석모형의 정확도(신뢰도) 저하를 발생시킬 수 있다.
구간 추정과 점추정에 대한 설명
= 점추정은 모집단의 모수를 하나의 값으로 추정해 주는 것이다.
= 구간추정은 모수가 포함되는 확률변수구간을 어떤 신뢰성 아래 추정하는 것이다.
= 우리가 아무리 좋은 추정방법을 사용한다고 하더라도
표본을 택하고 이 표본으로부터 계산된 추정값이 목표값을
정확하게 추정한다고 주장할 수는 없다.
= 구간추정은 점추청에 오차의 개념을 도입하여
모수가 포함되는 확률변수구간을 어떤 신뢰성 아래 추정하는 것이다.
가설검정에 대한 설명
= 검정통계량의 표본분포에 따라
채택여부를 결정짓는 일련의 통계적 분석과정을
가설검정이라 하며 일반적으로 몇 단계의 절차를 거쳐 검정이 수행된다.
나이대별 성별과 체중에 대해서 조사를 하고자 한다.
이때 발생 가능한 결측에 대해서 분류,
= 여성 체중 공개를 꺼림 : 무작위 결측
= 데이터의 누락 : 완전 무작위 결측
= 젊은 여성은 체중공개를 꺼림 : 무작위 결측
= 무거운(가벼운) 사람들은 체중 공개 가능성이 적음 : 비 무작위 결측
+ 추가 7
탐색적 데이터 분석 및 필요성에 대한 설명
= 수집한 데이터가 들어왔을 때,
다양한 방법을 통해서 자료를 관찰하고 이해하는 과정을 의미하는 것이다.
= 데이터의 분포 및 값을 검토함으로써
데이터가 표현하는 현상을 이해할 수 있다.
= 문제점 발견 시 본 분석 전 데이터의 수집 의사를 결정할 수 있다.
= 다양한 각도에서 데이터를 살펴보는 과정을 통해
문제정의 단계에서 인지 못한
새로운 양상, 패턴을 발견할 수 있다.
그러므로 새로운 양상을 발견 시
초기설정 문제의 가설을 수정하거나
또는 새로운 가설을 설립할 수 있다.
정준분석의 설명
= 두 변수집단 간의 연관성을 각 변수집단에 속한
변수들의 선형결합의 상관계수를 이용하여 분석하는 방법이다.
= 정준상관계수는 정준변수들 사이의 상관계수이다.
= 두 집단에 속하는 변수들의 개수 중에서
변수의 개수가 적은 집단에
속하는 변수의 개수만큼의 정준변수 상이 만들어질 수 있다.
일원분산의 정의와 특성을 연결시킨 것
= 하나의 인자에 근거하여 여러 수준으로 나누어지는 분석이다.
= 종속변수(등간 척도)와 정수값을 갖는 요인변수가
각 하나여야 하고 요인변수가 정의되어야 한다.
= A반, B반, C반 간 성적의 평균 차이가 존재할 것이다도
일원분산분석의 예이다.
군집추출에 대한 설명
= 모집단을 차이가 없는 여러 개 군집으로 나누어
군집 단위의 일부 또는 전체에 대한 분석을 시행한다.
= 모집단에 대한 추출기반을 마련하기가 어려운 경우 사용하면 편리하다.
= 표본크기가 같은 경우 단순 임의추출에 비해 표본오차가 증대할 가능성이 있다.
시공간 정의언어와 조작언어에 대한 설명
= 시공간자료 정의언어에는
시공간테이블 인덱스 및 뷰의 정의문, 변경문 등이
포함되어 있다.
= 시공간 조작언어는 객체의 삽입, 삭제, 변경 등의 검색문이 있다.
= 시공간자료 조작언어는 시간지원 연산자와
공간연산자를 포함하며 이를 통해 객체에 대한 공간관리와 이력정보를 제공한다.
가설검정에 대한 설명
= 검정통계량의 표본분포에 따라
채택여부를 결정짓는 일련의 통계적 분석과정을 가설검정이라 하며
일반적으로 몇 단계의 절차를 거쳐 검정이 수행된다.
이상치 발견의 통계적 기법 활용을 설명한 것
= 평균에는 집합 내 모든 데이터 값이 반영되기 때문에,
이상값이 있으면 값이 영향을 받는다.
가설검정의 결과로 가설 채택여부를 결정 시 설명.
= 제 1종 오류는 귀무가설의 참일 때
귀무가설을 기각하도록 채택할 오류이다.
= 제 2종 오류는 귀무가설이 거짓인데
귀무가설을 채택할 오류이다.
= 가설검정의 유의수준 a는 귀무가설이 참인데도
이것을 기각하게 될 확률을 말한다.
시간데이터의 정의와 의미 연결
= 유효 시간 : 객체가 발생하거나 소멸된 시간
= 거래 시간 : 관리 시스템을 통해 처리된 시간
=스냅샷 데이터 : 시간 개념이 필요하지 않아 거래, 유효시간을 미지원하는 데이터
+ 추가 8
확률에 대한 설명.
= 통계적 확률은 일반적인 자연 현상이나
사회 현상에서 일어날 가능성이 동일한 현상은 드물고,
분명하지 않은 경우가 대부분이다.
= 표본공간 S의 각 근원 사건이 일어날 가능성이 동등할 때,
사건 A에 대하여 n(A)/n(S)를 사건 A의 수학적 확률이라고 한다.
= 확률은 통계적 현상의 확실함의 정도를 나타내는 척도이며,
랜덤 시행에서 어떠한 사건이 일어날 정도를
나타내는 사건에 할당된 수들을 말한다.
= 통계적 확률 시행을 무한 번 반복시행하면, 수학적 확률을 값으로 수렴한다.
스튜던트 t분포에서 자유도에 대한 설명.
= 자유도는 자료집단의 변수 중에서 자유롭게 선택될 수 있는 변수의 수를 말한다.
= 자유도가 클수록 정규분포에 모양이 수렴된다.
= 자유도가 1보다 클 때만 스튜던트 t 분포에서 기대값은 0이다.
= 스튜던트 t 분포는 정규분포의 평균 측정 시
주로 사용하는 분포이다.
분포의 모양은 z 분포와 유사하다.
종 모양으로서 t=0에 대하여 대칭을 이루는데
t 곡선의 모양을 결정하는 것은 자유도이다.
상관분석의 기본가정에 대한 용어와 설명을 연결한 것.
= 동변량성 : x의 값에 관계없이 y의 흩어진 정도가 같은 것을 의미한다.
= 무선독립표본 : 모집단에서 표본을 뽑을 때 표본대상이 확률적으로 선정된다는 것이다.
일원분산의 정의와 특성을 연결시킨 것.
= 단일용인변수(독립변수)에 의해 종속변수에 대한 평균치의 차이를 검정하는 데 이용한다.
= 종속변수(등간 척도)와 정수값을 갖는 요인변수가 각 하나여야 하고
요인변수가 정의되어야 한다.
훈련데이터에 대해서는 높은 정확도를 나타내나
테스트데이터나 새로운 데이터에 대해서는
예측을 잘 못할 때 이를 뜻하는 명칭.
= 과대적합
비모수 통계의 특징을 설명한 것.
= 질적척도로 측정된 자료도 분석이 가능하다.
= 많은 표본을 추출하기 어려운 경우에 사용하기 적합하다.
= 가정을 만족시키지 못한 상태에서 그대로 모수통계분석을 함으로써
발생할 수 있는 오류를 줄일 수 있다.
= 비교적 신속하고 쉽게 통계량을 구할 수 있으며
결과에 대한 해석 및 이해 또한 용이하다.
+ 추가 9
요인분석의 대한 설명.
= 요인분석은 다수의 변수들 간의 관계(상관관계)를 분석하여
공통차원을 축약하는 통계분석 과정이다.
= 독립변수, 종속변수 개념이 없다. 주로 기술 통계에 의한 방법을 이용한다.
= 변수특성 파악을 위해 관련된 변수들이 묶임(군집)으로써
요인 간의 상호 독립성 파악이 필요하다.
= 요인에 대한 중요도를 파악하고, 필요가 없다면 제거하는 것도 필요하다.
수치자료
= 수치의 크기에 의미를 부여할 수 있는 자료를 나타내며
세부적으로는 구간자료, 비율자료가 있다.
상관분석의 기본가정에 대한 용어와 설명을 연결한 것.
= 선형성 : 두 변인 X와 Y의 관계가 직선적인지를 알아보는 것으로
이 가정은 분포를 나타내는 산점도를 통하여 확인할 수 있다.
= 두 변인의 정규분포성 : 두 변인의 측정치 분포가
모집단에서 모두 정규분포를 이루는 것이다.
= 무선독립변수 : 모집단에서 표본을 뽑을 때 표본 대상이 확률적으로 선정된다는 것이다.
= 동변량성 : X의 값에 관계 없이 Y의 흩어진 정도가 같은 것을 의미한다.